Pre-labelled synthetic documents for healthcare and insurance extraction
Every document ships with ground truth, bounding boxes and a scanned variant. Built for teams shipping document AI in healthcare and insurance.
Three buyer profiles
ML engineers, procurement leads, data platform teams. Different jobs, same RCA libraries.
Shipping healthcare or insurance extraction to production
You need labelled training data and a regression suite that catches regressions before they hit a customer document. RCA libraries give you pre-labelled PDFs, ground truth, bounding boxes, and scanned variants in one bundle.
Evaluating extraction vendors against a real-world target
You need every vendor to score against the same documents and the same ground truth. The Insurance QA Sprint Pack ships 10 complete submission packs with engineered red flags. Same input, same target, fair comparison.
Deploying document extraction inside your own environment
RCA Extract runs as a self-hosted Docker container in your cloud or on-prem. Zero data egress. Customer-managed compute and costs. Your existing RBAC and audit policies apply.
Real pages from the libraries
Real pages from the RCA Insurance and Medical libraries. Same generator stack, different document types. Every page ships with ground truth, bounding boxes, a scanned variant, and a visible synthetic disclaimer.







Free. Same-day delivery. Two complete insurance packs or 25 to 35 medical documents, with ground truth and scanned variants.
What we ship
Three product lines from the same generator stack, plus benchmark packs and custom libraries.
RCA Extract
Self-hosted document extraction for healthcare PDFs. Discharge summaries, ED assessments, referrals, imaging and pathology reports. Ships as a Docker container that runs in your cloud or on-prem. Built and tested against the RCA Medical Library.
See the supported typesRCA Insurance Library
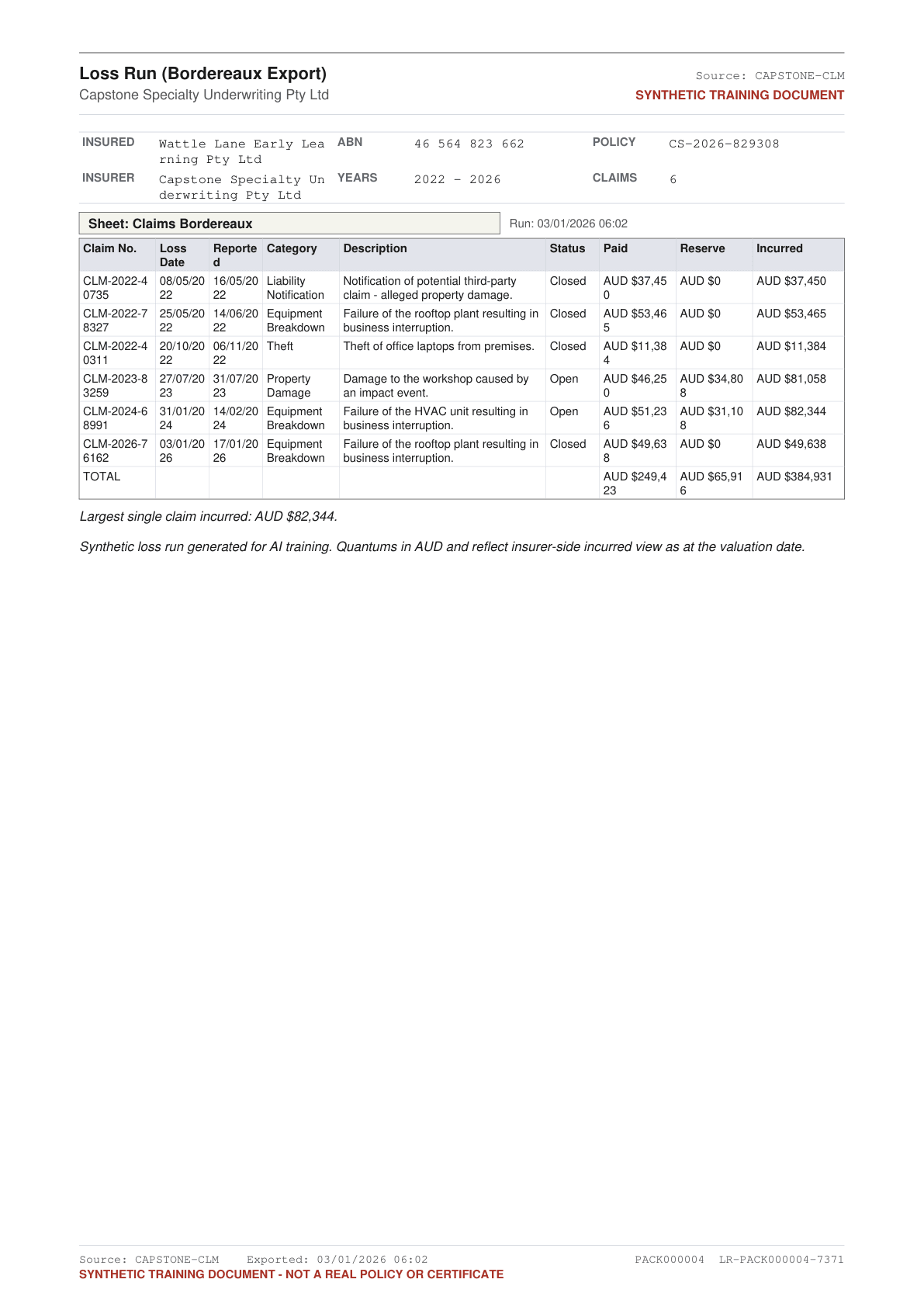
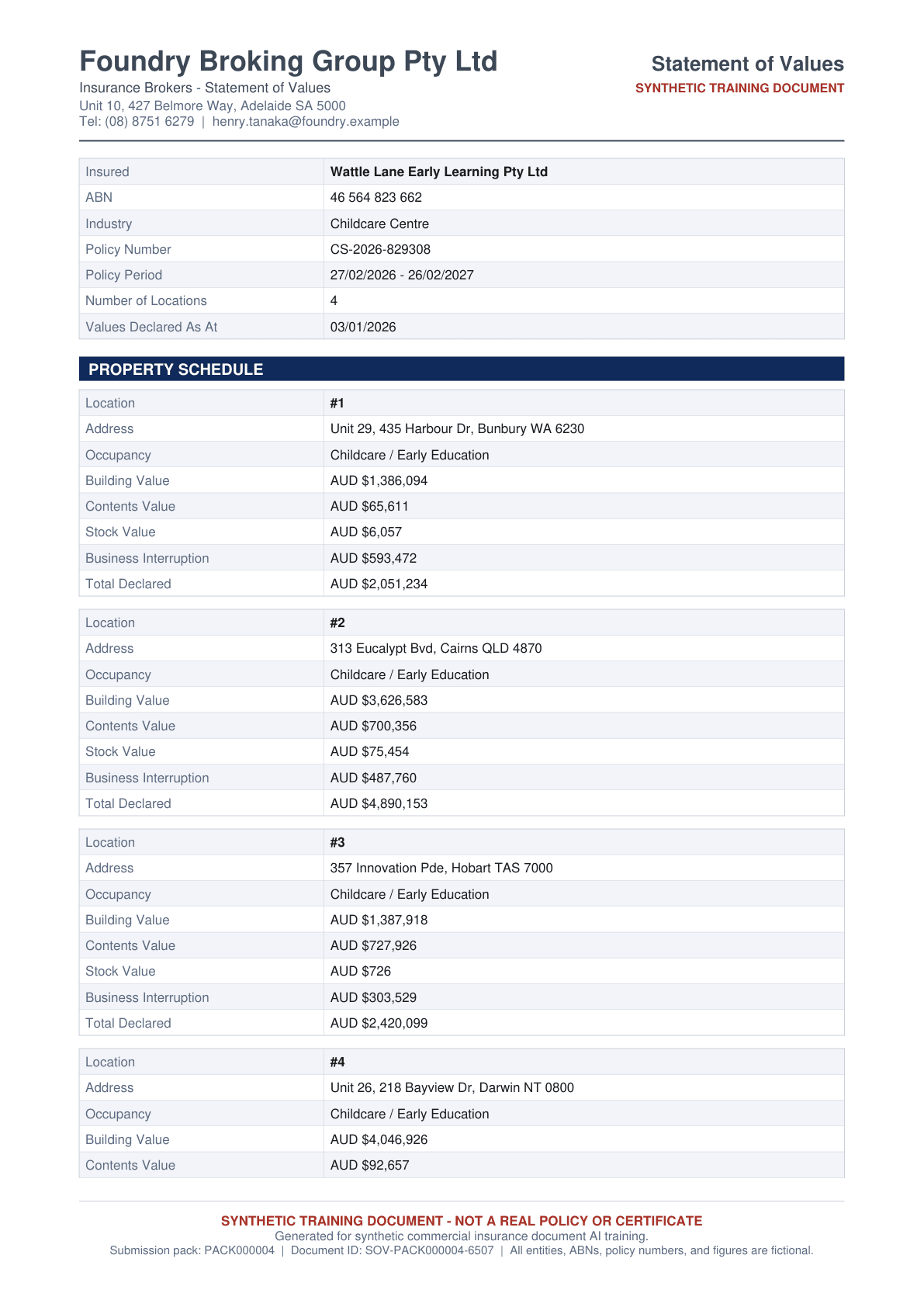
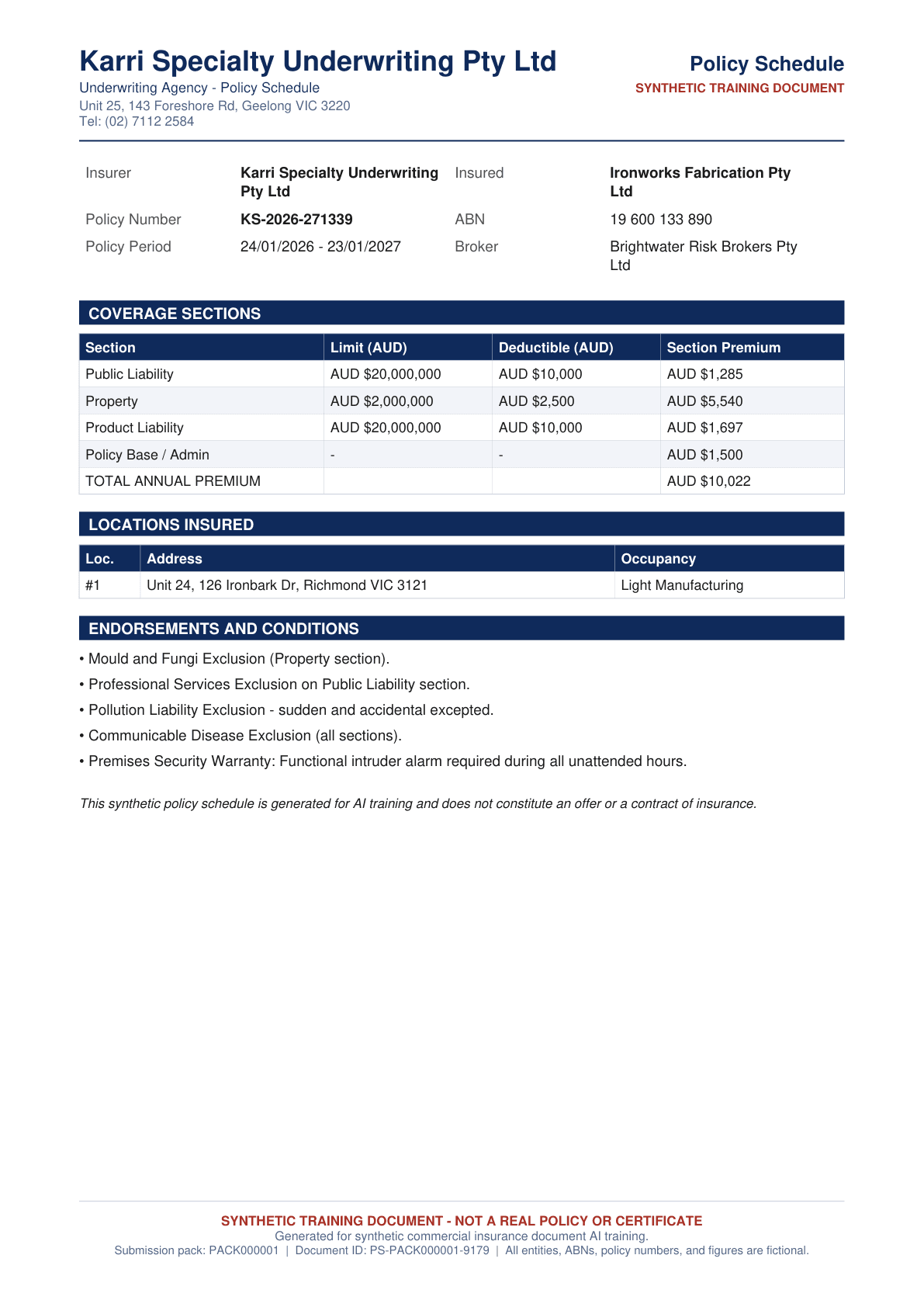
Synthetic commercial P&C submission packs. Broker emails, loss runs, statements of values, policy schedules, certificates of currency, applications, FNOL forms, claim reports. Engineered red flag categories. Per-claim and per-location bbox rows.
See the pack structureRCA Medical Library
Synthetic Australian medical training documents. 40+ document types across hospital, ED, GP clinic, pathology, imaging and specialist correspondence. NSW postcodes, Medicare format, provider postnominals.
Browse the document typesRCA Benchmark Packs
Smaller paid review packs, QA packs and pilot packs that sit on top of the libraries. Use them for procurement evaluation, vendor comparison or pre-rollout QA. Insurance QA Sprint Pack ships at AUD $2,500.
See the pack menuRCA Custom Libraries
Your document types. Your field schema. Your style profiles. Built deterministically and shipped with ground truth and bounding boxes.
Scope a custom libraryWhy teams pick the RCA libraries
Six properties that matter for QA, training and procurement evaluation.
Real-looking PDFs, real variety
Visually varied across eight style profiles and three template families per document type. Not one template repeated.
Ground truth shipped with every document
CSV and JSONL. Bounding boxes on every labelled field. Insurance documents add per-claim and per-location row entries, each row with its own bbox.
Scanned variants for the photocopy path
Every clean PDF ships with a rotated, noised, JPEG-compressed scanned variant alongside it. Same ground truth, harder input.
Reproducible by seed
The same seed produces the same PDFs every time. Useful for versioned QA, regression suites, and procurement evaluation.
Safe to share inside your company
Every page carries a visible synthetic disclaimer. Nothing is real patient, claimant, broker, or policyholder data. No data agreement required to redistribute internally.
Direct delivery, no third parties
Libraries ship as direct downloads. No third-party file-share processor unless requested. RCA Extract runs as a self-hosted Docker container with zero data egress.
How the libraries are built
A deterministic Python generator, curated case files and phrase banks. No LLM calls in the default pipeline.
Curated case files
Hand-authored case archetypes. Phrase banks. Field schemas defined up front.
Deterministic generator
A Python pipeline turns a case file plus a seed into a fully-rendered PDF. Same seed, same output, every time.
Labels generated alongside
Ground truth, bounding boxes and scanned variants are produced in the same pass as the PDFs.
Library packaging
Library ships with manifest, splits, README and a written synthetic safety statement.
Synthetic by design. Safe to share.
Every document we ship is computer-generated. The names, ABNs, Medicare numbers, addresses, phone numbers, policy numbers, claim numbers and dollar values are all synthetic. Every PDF page carries a visible synthetic disclaimer.
- Not for clinical, claims, underwriting, regulatory, accounting or legal use.
- RCA Extract runs as a self-hosted Docker container inside your environment. Zero data egress. Inherits your existing RBAC, audit and access policies.
- Library deliveries are direct downloads. No third-party data processors involved.
- No real customer or patient data is held, transmitted or stored anywhere in the generator or the libraries.
Try the libraries in five minutes
Request the free 2-pack insurance preview or a 25 to 35 document medical review pack.
No credit card. Same-day delivery. Each pack ships with a README_START_HERE.md and a recommended five-minute review path.
Built and supported from Sydney, Australia. More about Root Cause Analytics